Abstract
In this project, we present a large-scale evaluation of various jailbreak attacks. We collect 17 representative jailbreak attacks, summarize their features, and establish a novel jailbreak attack taxonomy. Then we conduct comprehensive measurement and ablation studies across nine aligned LLMs on 160 forbidden questions from 16 violation categories. Also, we test jailbreak attacks under eight advanced defenses. We identify some important patterns, such as heuristic-based attacks could achieve high attack success rates but are very easy to mitigate by defenses, causing low practicality.
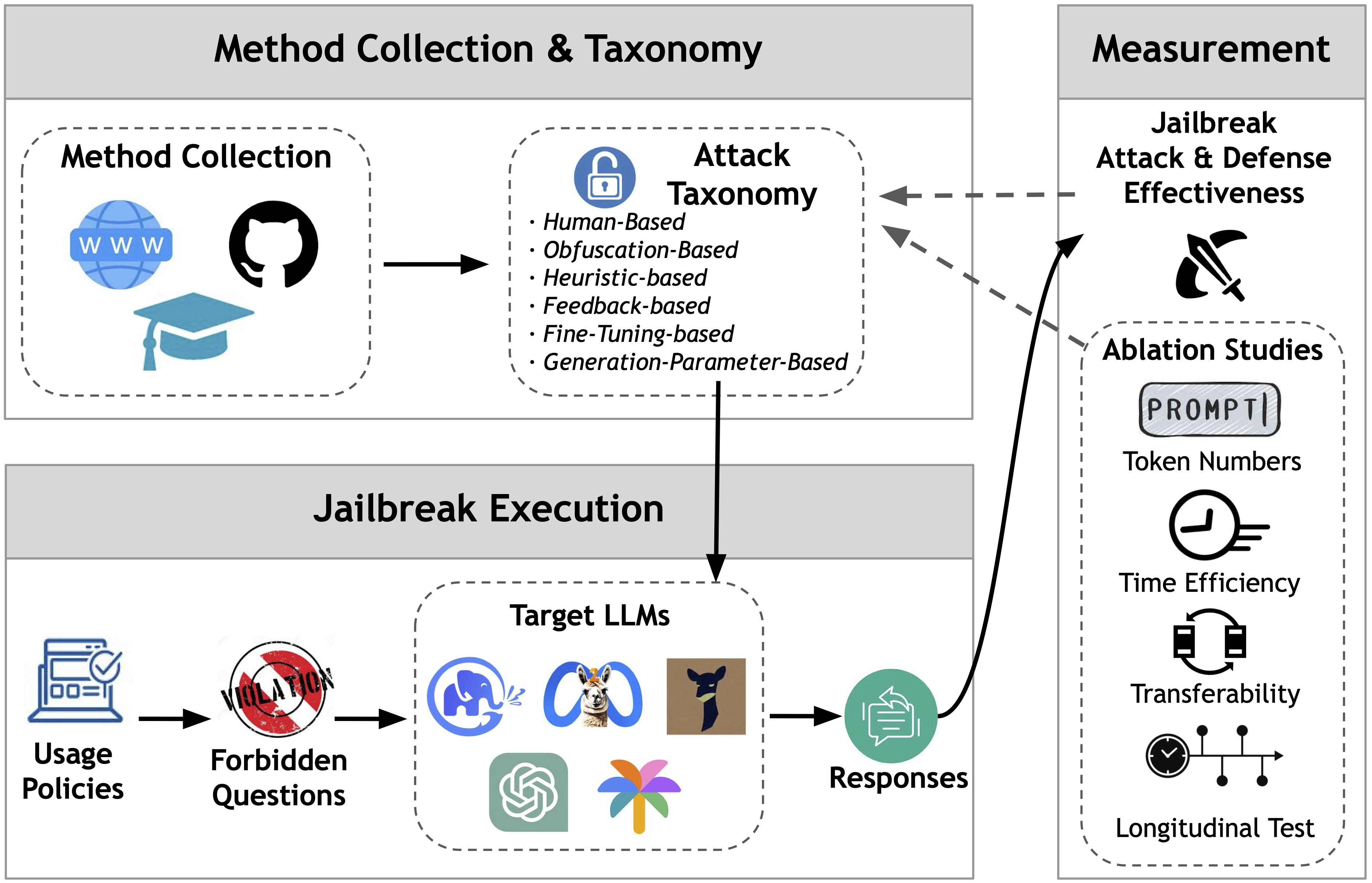
Jailbreak Taxonomy
We classify the methods based on two criteria: (1) whether the original forbidden question is modified; (2) how these modified prompts are generated in the method.
Unified Usage Policy
We collect and summarize the usage policies from five major LLM-related service providers (Google, OpenAI, Meta, Amazon, and Microsoft).
Unified Settings
We align the experimental settings, especially the number of steps in the optimization process, to provide an unbiased and fair experimental setup as much as possible.